artifacts
research, engineering, and technical notes
Deep learning can solve non-trivial problems in nlp
Originally posted: 12/06/20
Deep learning is thought of as the ability of a class of algorithms to learn a hierarchical set of representations from lots of data, which means it can learn low, mid and high level features. You specify the input/output and your networks optimization algorithm updates the weights that determine how each input feature will affect the output prediction.

These updates are analogous to a programmer coding a bunch of rules to solve a problem, but with deep learning, sometimes you can end up with code better than what any programmer could write.
We can narrow this down with something more tangible, so let’s use named entity recognition by way of language models as an example.
We can rely on 3 strengths of applying deep learning to this problem space.
-
NER benefits from the non-linear transformations made in deep layers, which generates non-linear mappings from input to output. Compared to linear models, deep learning based models are able to learn complex and intricate features from data via nonlinear activation functions.
-
Deep learning saves significant effort on designing NER features. Traditional feature-based approaches require a considerable amount of engineering time. Deep learning models are extremely effective in automatically learning useful representations and the underlying factors from raw text.
-
Deep neural named entity recognition models can be trained in an end-to-end paradigm by way of gradient descent. This allows us to design NER systems from complex annotation policies.
Theory
Theoretically, many layers should enrich the levels of the features.
For example, in the shallow layers of the network, we can imagine it looking at the character level of words…

…before looking at whole words…

…and arriving at the deepest layer to learn the most distant relationships between the parts-of-speech and the dependency relationships between words and phrases.
In a way, deep learning goes against the intuition that linguistics gives us. That linguistic features like parts-of-speech, constituency and dependencies should be all we need to parse and extract the differences between concepts in text and language to learn complicated contextual information. But I am prepared to assert that in the field, linguistic features are not enough on their own to help computers with meaning representation. Most linguists would be up in arms over this, and fair enough, it breaks their entire universe.
It’s easy to say that language models are simply mimicking what they see and that to achieve full natural language understanding they need a deeper understanding of the underlying mechanisms behind language. For the most part this seems like criticism for the sake of criticism. You know, the kind of hand-waving that doesn’t move anything forward? I agree that we need a more granular understanding of the innate structure of language, specifically semantics and reasoning applied to machines so they can effectively use compositionality to understand language the way we humans do, but science takes time.
Traditionally(about 3,000 years), the scope about how human brains compute during the processing and understanding of language has been pretty limited to humans, and when this view of the world has been applied to machines it was largely confined to abstract theoretical concepts. Developing applications that facilitate language interfacing via meaning representation is fairly recent(about 70 years) and it is a hard task.
This line of thinking that linguistics is enough, or that we can only achieve this though a better understanding of linguistics is similar to what symbolic expressions were in AI from the mid-1950s to the late-1980s(what a surprise, science moves slowly). That cognition is symbolic, and our thoughts are symbolic just because that’s what we see, say and imagine. But this turns out to not be a singular truth, as it’s more likely that thoughts are a series of abstractions that follow complex sequences in a process that we cannot yet formally explain.
{kind=link}
Maybe linguistic feature sets can be used for very simple use-cases or to optimize some process downstream, but semantics are hard which makes it difficult to reduce problems to limited feature sets. For example, in more conventional NLP problems, if you’re topic modelling you have an overall unambiguous theme, like the technology company Apple, you can look for all sentiment, mentions or entities relating to this one theme. But if you’re working with a wide range of terms that represent themes from a wide range of classes, this makes it hard to pin down uniformity across tasks like keyword extraction using conventional methods.
I think it would be fair to say that a method that can generalize and be penalized when it gets things wrong would actually be a better way to frame the problem. The ideal approach would be to integrate symbolic and connectionist views of the world, but the one that lacks biological rigor cannot survive without the other.
But it makes sense to me why this view of the world is so popular. There’s a continuing bias towards computers needing to be 100% correct all the time because classical computer science is a discrete math and by that logic everything needs to be 100% correct to function. Trying to come up with a rule for everything falls in line with how we think about computer science and its obsessive nature of trying to account for every single detail of a program within a set of convergence bounds.
When it comes to applying machine learning to complex problems, there’s usually nothing exact about complex things and we need to consider that we want to automate processes that are often nuanced. So some problems need generalization, which makes a 100% rules based view of the world economically unfeasible and is probably why projects like the Semantic Web cannot secure funding.
In any case, a future where computers achieve a human-level of understanding of the fundamental principles and properties that make up language and cognition will likely be realized through a reconciliation between the imperfect pragmatic and imperfect theoretical perspectives of how the world works.
But I digress, are building neural networks as easy as adding more layers to the network?
More layers do allow the network to learn more fine grained features, but in reality sometimes training gets worse, not better when you stack lots of layers, making it harder for the network to choose parameters from the feature space.
Application
The best approach to this would be to use a network architecture that can take advantage of having many layers and not be affected by the vanishing gradients during gradient descent as the network gets deeper.
One way to frame the NER problem is to train your task using the transition-based, bloom embedding residual CNN state-machine provided by spaCy.
This transition-based state-machine takes a page from the dependency parsing community’s use of shift-reduce parsers by using 3 transition operations(actions) to change the state of the input sequence.
SHIFT, REDUCE, OUTPUT.
This “state machine”…

…uses 3 stack data structures (one called the buffer(also sometimes called queue). Items from the buffer go to the stack, and from the stack to the output to move (SHIFT) the first word in a sentence from the head of the buffer (contains words to be processed) to the stack (where the words will be further processed).
So we start with an empty stack, all words from the sentence are on the buffer and we have no entities affixed to the words.

During this collection and parsing of the text, something called a resCNN is making the decision of which named entity label to assign to which words or if a label should be assigned to any particular word at all.

When assigning and fixing the label to a token, the resCNN incrementally parses the input with Bloom embeddings and defines a probability distribution over each action given the current contents of the stack, buffer, output and the history of each action taken to predict the sequence of actions the 3 operations should take to parse the input sentence.
When a token or collection of tokens from a sentence in the buffer are moved to the stack, the resCNN will decide if these tokens belong to a particular entity during the REDUCE step, from which the tokens are popped from the top of the stack onto the OUTPUT stack and given an entity label.
Then it looks at the next word in the sequence to repeat these actions. The algorithm completes when the buffer and first stack are both empty.
Words can also be moved from the buffer directly into the output stack when the word should not be labeled.
So we SHIFT once and [Christian] moves from the buffer to the stack. We SHIFT again and [Hardy] joins [Christian] on the stack as [Christian, Hardy]. The REDUCE operation is then used to put [Christian Hardy] on the OUTPUT stack and adds the label PERSON as [(Christian Hardy)-PER].

Spacy bakes in a way for the algorithms to say some actions are valid and some are invalid, which is useful because if we show the algorithm training examples that we do not want tagged, the final model will not make predictions on words it’s not sure about.
So when it’s calculating which action to take next, if one entity is predicted upstream and we move to the next potential entity to be tagged and the word is scored as “o” (outside of an entity aka this word is not an entity) the algorithm knows this word is not a valid entity and will not make a label prediction. This means the sequence that’s predicted should always be a valid sequence because we have a way to block out noise.
It’s worth noting that this framework is very flexible because the resCNN can define multiple configurations of the transition operations. After the state machine is trained on the labeled examples, it’s REDUCING from the stack to the output, making hundreds of thousands of predictions on new input sentences based on different sequences of word combinations, and updating the learning gradient if an entity label is wrong, optimizing itself so it can make better predictions. Which is why this method is able to come up with good solutions for structured prediction tasks.
For example, if you have a set of text where the context is very free and relational patterns are hard to extract via their parts-of-speech, dependencies or frequencies, framing the problem this way allows you to flexibly calculate features and tune the prediction task to the domain text so that you can read a sentence from it, maintain some sort of state, manipulate that structure with some universal set of actions and penalize the algorithm when it gets things wrong so it can learn to make the right associations.
Earlier I mentioned something called a resCNN (residual convolutional neural network) that predicts the label to fix to our words. They are based on the concept of a Resnet, made popular in 2015.

Because of them we can train a deeper network and the learning gradient has a shortcut that it can take in the learning process during backpropagation and that gradient will not vanish.
The resCNN solves this problem by adding skip connections which take the activations from early layers, skips a couple and then feeds them to layers that are deeper in the network. By doing this you can effectively train deeper networks and learn better features.

Activation functions are necessary to squish the input received from the previous hidden layer down into a small range of values. Without this, we would not be able to learn non-linear relationships. They elongate and squash the layers in space…
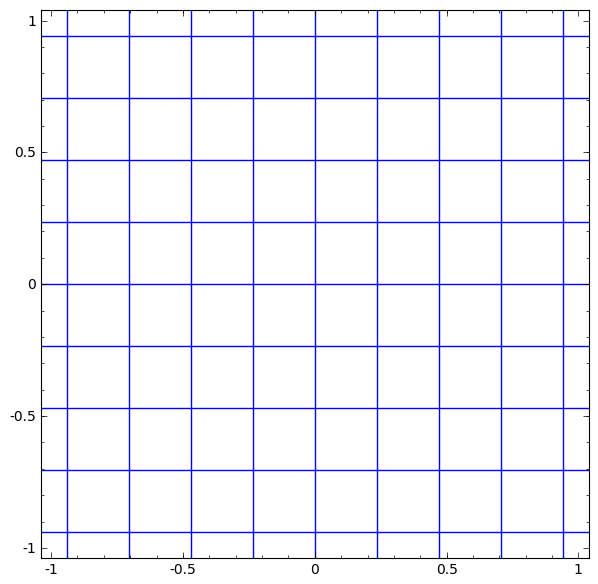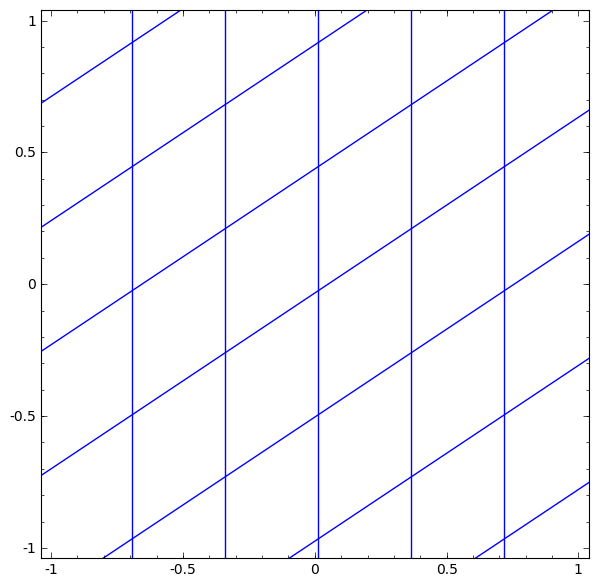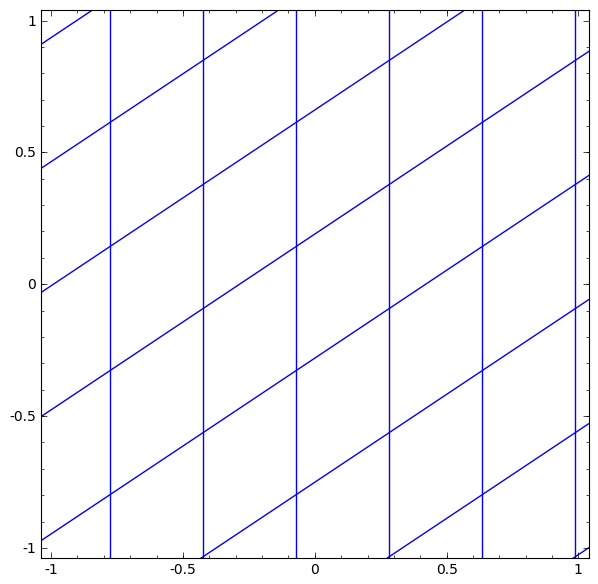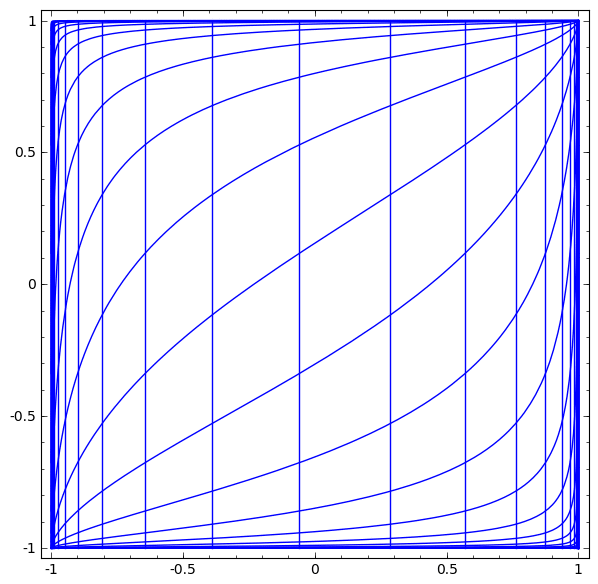
…which is the layer trying to approximate the distribution of the input data’s topological properties…
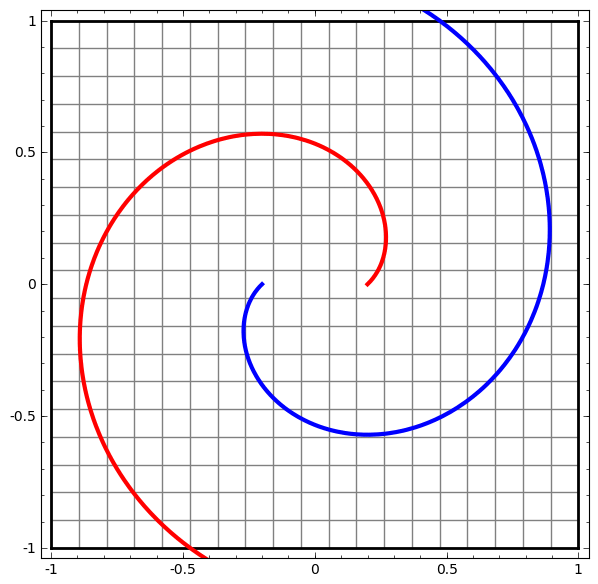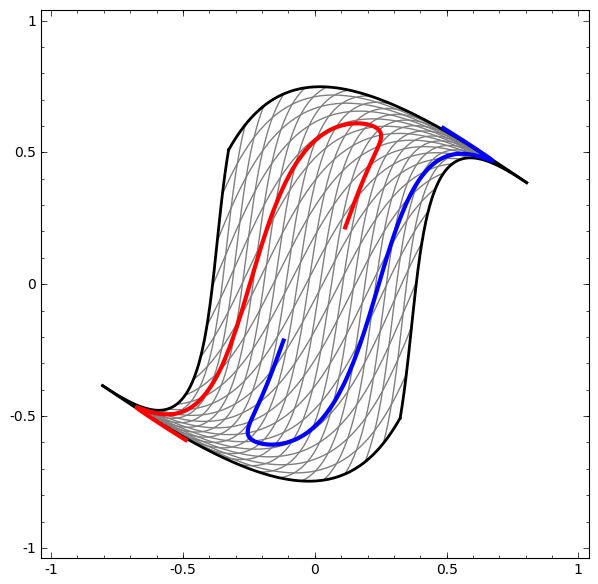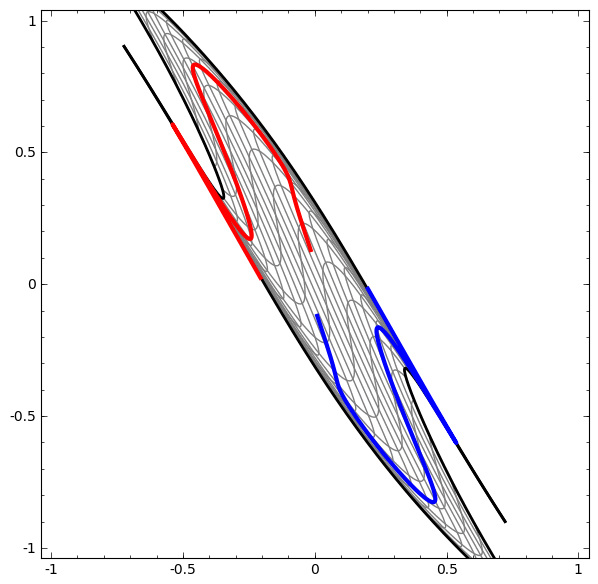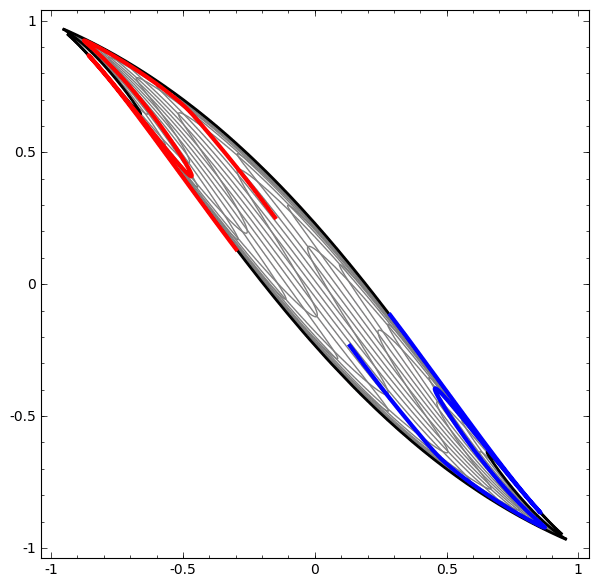
…and without skip connections, it’s harder for the deeper layers to learn from linear activation functions during gradient descent.
Non-linear activations help with this somewhat, but essentially they all have some disadvantage of slow convergence, vanishing/exploding gradients, they’re computationally expensive, and some are only suitable for output layers.
Maybe we need a better optimization algorithm?

In any case, we can explore this with a sensitivity analysis and look at gradient descent’s effect on the input space to maybe interpret what’s happening with the data as it goes through deeper layers. In any case, skip connections help give us an advantage.
Words are highly dependent on the company they keep, so when they’re represented as Bloom embeddings the distribution of the target words or phrases that we would like to tag can be learned in context during the first step of learning.
This allows us to learn about the input distribution of the incoming sentence from a set of compressed sentences (to maintain network efficiency) and allows the buffer and stack to interact with each other and efficiently check whether a token is a member of its respective set, as the final layer in the resCNN makes its prediction of the state of the input sequence operations. The lower the dimensionality of our inputs, the less memory we use because parsing web-scale text is computationally taxing and the network can make faster decisions. This representation is also easily reversible, so the output vectors can be mapped to their original tokens at prediction time.
So, Bloom embeddings are prefered here because they give us a very basic data shape that we can manipulate very easily using similarity operations that let us easily feed our labled input forward through a neural network as a dense embedding where it becomes a vector that represents the sentence…

…where a sequence of sentences would hold multiple meanings…

…and a final matrix representation would let us learn the meaning of sentences in context.

This helps take into account the ordering of words, which plays a big part in helping computers to understand the syntax and semantics of human language.
So if we train a state-based system on a piece of text like this…

…it’s able to recognize the statistical distributions of Christian and Karen are very similar. The same can be said with Belgrade and Valencia…

…and for any name, location, subject, object or just about anything we would like.

The takeaway here is that we can say that certain things are related and we can process them in similar ways to derive meaning. That’s a very useful type of knowledge to have because we don’t have to fully rely on expert/symbolic systems to define a computer’s view of text or the world.
So instead of having a fixed view of an embedding table and saying that all words outside of the table share a single out-of-vocabulary vector, this snippet of code will allow us to mod the words into the table so we have some long hash string and lots of words will end up with the same vector representation.
The feature object extracts four attributes from each token in a document that gives us a fuzzy, zoomed out shape of words to which the layer can learn, each column is then embedded into a table using the hashing trick to map the labeled input, which allows each word to have a very distinct representation. This embedding strategy is great because its computationally inexpensive and you can end up training your task with very few rows. As little as 400 would start to produce good results. Each of the four features output a vector, they are combined into another function which outputs a vector that is the concatenation of each of their pieces, which are then fed forward to a multi-layer perceptron of one hidden layer and a Maxout activation function.
features = doc2array([NORM, PREFIX, SUFFIX, SHAPE])
norm = get_col(0) >> HashEmbed(128, 7500)
prefix = get_col(1) >> HashEmbed(128, 7500)
suffix = get_col(2) >> HashEmbed(128, 7500)
shape = get_col(3) >> HashEmbed(128, 7500)
embed_word = (
(norm | prefix | suffix | shape)
>> Maxout(128, pieces = 3)
)
The key takeaway is that the majority of words in our text are going to end up with unique representations, so the model is always able to learn new words in our vocabulary.
During the second step, we encode sentences from the data as token features in the shape of vectors, which represent the tokens in context. Now we can learn that phrases have different meanings, even if those phrases are processed into separate tokens. We can think of this as each vector being encoded with information from the surrounding context of other vectors.
So we end up with word representations that are specific to the types of problems that we’re dealing with. The resCNN does this by creating a window around either side of our words to extract them. The most important part here is the trigram layer, which takes a window on either side of the word, concatenates them together so that if we end up with something like 128 dimensions on either side of the word, we’ll end up with 384 dimensions for each word.
From there, a multilayer perceptron with a Maxout activation is used to take that input representation and map it back to 128 dimensions. So we’re mixing the information from the two words on either side of our target word to produce an output vector that is of the same dimensionality. So we relearn what this word means based on the company of words it keeps on either side.
trigram_cnn = (
ExtractWindow(nW = 1) >> Maxout(128, pieces = 3)
)
When we stack 4 of these residual layers, we end up with 4 representations of vectors that are sensitive to the context of the words on either side of the target word.
So in the first layer we’re sensitive to 1 word on either side, in the second layer we’re sensitive to 2 words on either side, in the third layer we’re sensitive to 3 words on either side and finally in layer 4 we’re able to look at 4 words on either side of all words. The residual connection has an interesting effect in that the output space from each connection is likely to be similar to the output space of the input. So the spacy input vector isn’t changing that much which helps the network keep the context of the words as structured as the original input while trying to learn its context.
encode_context = (
embed_word
>> Residual(trigram_cnn)
>> Residual(trigram_cnn)
>> Residual(trigram_cnn)
>> Residual(trigram_cnn)
)
In the third step, the network needs to learn what to pay attention to. It’s not like the attention we’re all used to from transformer heads, it’s more like a summarization of the inputs by taking one vector per word…

…and calculating a vector based on the surroundings of that target word or the weighted summary of each vector calculated in context.
This is basically manual feature extraction, but can be understood in the same way. So you take the first word immediately before the buffer, the word immediately after it then we take the vector assigned to the first word of the previous entity, the last word of the previous entity and the last word of the entity before that to manually start our feature extraction. By doing it this way we can come up with an arbitrary number of feature functions to parse text through the stack and buffer to come up with elegant ways to find the entities for our problem.
state2vec = (
tensor[state.buffer(0)]
| tensor[state.buffer(-1)]
| tensor[state.buffer(1)]
| tensor[state.buffer(0)]
| tensor[state.buffer(-1)]
| tensor[state.buffer(1)]
) >> Maxout(128)
The network will learn how to predict the labels of the target based on a simple multi-layer perceptron step. It is here that the network acts as the controller of a state-like machine to make the predictions of the transition-based parser, taking the first word from the buffer, the word immediately before it, after it, the first word of the previous entity and the last word of the previous entity. After the features have been calculated for the state, we can look arbitrarily far back into the text so it doesn’t matter if the previous entity that was assigned was 100 or 1,000 words back, we can still condition on those probabilities.
tensor = trigram_cnn(embed_word(doc))
state_weights = state2vec(tensor)
state = initialize_state(doc)
while not state.is_finished:
features = get_features(state, state_weights)
probs = mlp(features)
action = (probs * valid_actions(state)).argmax()
state = action(state)
When we put some of this logic together, the final actions of assigning the appropriate label is executed and when the best valid action is performed, the state-machine will go back to the next state and then proceed forward in the loop. A tensor embeds the words in the document which is fed to a CNN to consider the context of sentences, the state is initialized and we then step through the actions of the state-machine to get the probability of an action and penalize the validity of an action given the state. So basically what I’m saying is:

They’re very cool and all, but trying to bake the assumptions about the problem into the training data as much as possible is one of the most important steps of solving the problem, because architectures and methods will continually change, but understanding the business requirements in an applied setting will always be in fashion.
Breaking the problem down into small simple tasks, where you understand the meaning of your entities, therefore understand the objectives of the output so you can perform experiments as quickly as possible will always be the best first step.
For example, if you’re trying to distinguish between two entities that are ambiguous by nature and it’s even hard for humans to tell the difference between them, a lot of thought would need to go into how you’re making the distinctions between the two categories based on how they will be used downstream, and building a dataset that accounts for these concepts would be necessary.
In theory we can take advantage of all the encoded features in unlabeled text so that we’re not limited to just the text that we have annotated, but for my current problem, I have yet to see success with this, I’ve mostly seen massive overfitting to the training data.
For the specific problem I’m working on right now, pretraining the embedding layer may help to determine what the model will be capable of. Fine-tuning the pretrained text on the entities to be used helps a little bit, but ultimately sourcing more data will give you a very big win.
Doing well on the training set is also a prerequisite to doing well on an evaluation set or test set, because if the model cannot learn during training it will not produce anything that you can use on an evaluation set or otherwise. So good performance on the training set is a good first step to developing something useful.
Resources to train these models can also present potential bottlenecks, because deep learning is a data intensive and computationally expensive process. Under the right conditions you can do a lot with a little, but this always depends on your problem.
References
Lample, Ballesteros, Subramanian, Kawakami, Dyer, Neural architectures for named entity recognition, Carnegie Mellon University, The NLP Group at Pompeu Fabra University, 2016.[1]
Li, Sun, Han, Li, A survey on deep learning for named entity recognition, IEEE Transactions On Knowledge and Data Engineering, 2020.[2]
Moschitti, Basili, Complex linguistic features for text classification: a comprehensive study, Human Language Technology Research Institute at University of Texas, Computer Science Department at University of Rome Tor Vergata, 2004.[3]
Honnibal, Embed, encode, attend, predict: The new deep learning formula for state-of-the-art NLP models, Explosion.ai, 2016.[4]
Olah, Neural Networks, Manifolds, and Topology, 2014.[5]